Introduction
PYTHEAS1 (Powerful Yet Tactfully Helpful Electronic Arranger of Sources) is designed to be a multi-tier ILS (Integrated Library System) or Library Application Framework (LAF)2. The two major building blocks for providing server-based metadata and information retrieval capabilities in PYTHEAS are MARC (MAchine Readable Cataloguing) and RDF (the Resource Description Framework), standards that define a format for describing objects and can package highly structured metadata for describing content and content relationships in physical and digital objects. The database also has some support for Web Ontologies and Topic Maps. The server architecture is based on XML (eXtensible Markup Language), Web Services, and EJB (Enterprise Java Beans). We make use of Exolabs Castor XML mapping tool to manage XML in a database-independent manner.
The latest version of of the source can be found here and a demo can be found here (please note that the host machine is several years old and supports several other applications so be gentle, it's a small collection but possible searches include "java" and "perl"). The overall architecture for PYTHEAS can be seen in the following diagram:
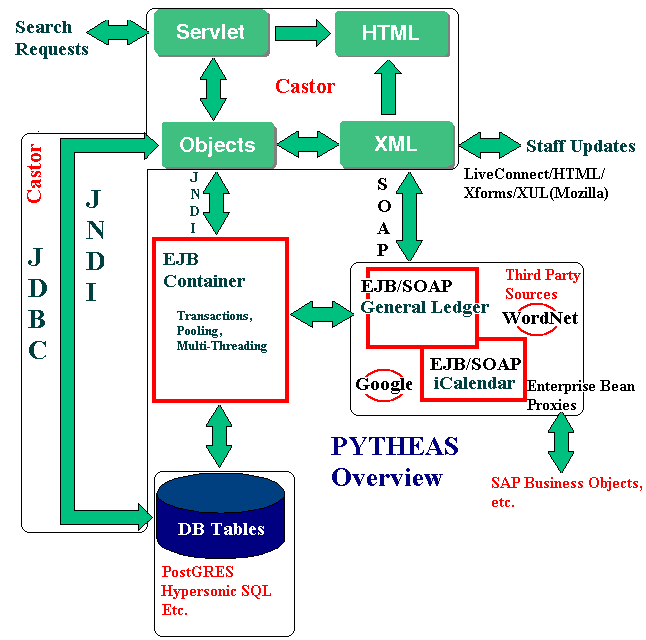
XML Layout
In order to understand how PYTHEAS uses XML, it is important to understand that Castor is a Java-based Object/Relational mapping tool that can provide an XML view of a database. On the plus side, these "views" can be varied, allowing for example, a "full" and "brief" mapping, and allowing a node to be switched from an "element" to an "attribute" and vice-versa on the fly. Sometimes, though, the XML view is a little too dependent on the structure of the underlying database. For example, most OSS RDBMS options limit text fields to 255 characters, leading to results like the following:

Here the 505 field is broken into three parts, and requires either the XML to be modified on the way out (which isn't that big a deal) or merged by a stylesheet. You can see it up close here. Again, this is dependent on the underlying database, Castor will faithfully map to whatever the database allows, but this is why a full text document may not be a good match for RDBMS varchar fields.
A full treatment of MARC and RDF is far beyond the scope of this document, but some background information may be useful to understand the XML representation used in PYTHEAS. With MARC, conceptually distinct segments or "fields" of information are identified by 3 character numeric codes called tags. Within each field, elements are organized through the use of "subfield" codes consisting of a single letter or number preceded by a "delimiter" sign. Fields may be fixed length or variable in size. Within variable fields, the first two character positions contain values that interpret the data found in the field. Fields and subfields may be repeated, allowing the MARC format to support an incredible level of content and detail. The MARC formats supported in PYTHEAS are for bibliographic, holdings, and authority records. MARC 21 support has yet not been put into the mapping files and not all of the fields for authorities and holdings have been specified. The mapping file should be modified to list all possible MARC 21 fields and a view should be defined for each record type, but this is fairly straightforward to add.
The trickier MARC-related construct is authorities. Authority Control seeks to improve quality and consistency in the database. Perhaps no other aspect of library databases demonstrate better demonstrate the tremendous intellectual effort libraries have put towards organizing information than the many different kind of relationships accommodated by authority work. The relational model is very good for "many to many" relationships, e,g., many books are about "environmental studies", and immediate updates, e.g. "environmental studies" becomes "environmental earth studies", but raises some issues when updating records directly by XML. For example, if a work is updated to reflect that it is no longer about "environmental studies" then the reference in the many table needs to be removed. This can be dealt with during the update but requires some extra plumbing in the processing.
RDF is arguably more grounded in XML and allows metadata to be packaged in XML based on a schema, or collection of classes that represent a common vocabulary. Various research communities or groups with a common interest may define these schemas. We use a Dublin Core/MARC Crosswalk to create a base metadata set and use NACO Normalization Rules to create an element for string matching in queries. RDF is envisaged as the backbone of most searching in the database, although every effort has been made to fully take advantage and expose the power of MARC, the public side of the system will almost certainly be layered on top of RDF.
EJB/SOAP & Castor
Castor can be a persistence engine for an EJB implementation and makes it easy to process SOAP requests. With EJB and SOAP, it is possible to build distributed applications be combining components from different sources, for example, a general ledger bean for acquisitions processing. ILS vendors typically develop these layers from the ground up, EJB/SOAP helps to directly combine our efforts with those of other Open Source and commercial EJB/SOAP initiatives, in addition to legacy systems through proxies. For example, using IBMs Business Objects or SAP through a connector. The current distribution includes a servlet-based SOAP server and a sample client.
Ontologies & Topic Maps
Web Ontologies and Topic Maps veer into that contentious territory know as the Semantic Web (SW), and it is far beyond the scope of this document to tackle the issues surrounding the issues of knowledge representation on the Web3. However, regardless of one's feeling about the ultimate utility of futility of the SW, it is our belief that both of these areas provide a useful syntax and an opening for leveraging mainstream technologies for information retrieval. Topic Maps may also hold special utility for IFLA's Functional Requirements for Bibliographic Records (FRBR). With Topic Maps, it is possible to create "associations" such as "is_realized_through" for Work and Expression, and "is_exemplified_by" between Manifestation and Item. The current data loader creates very simple Topic Map objects but this area is ripe for further exploration.
Searching the Database
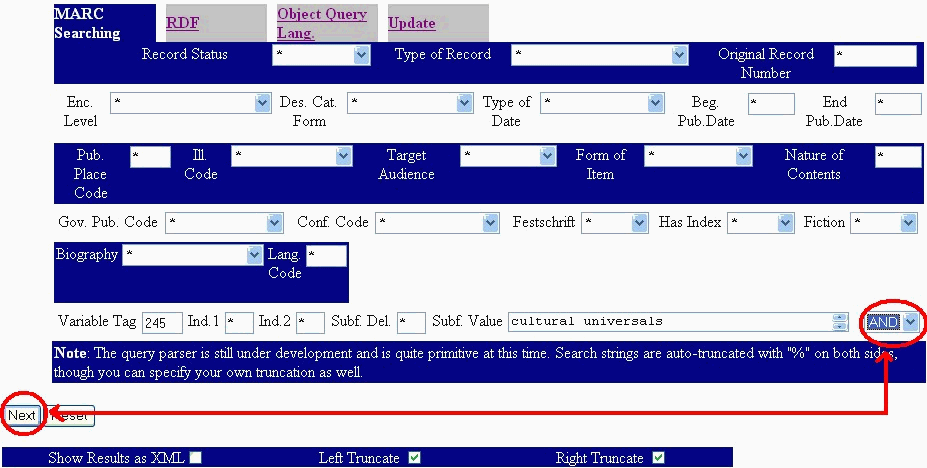
The interface and the form parsers need a tremendous amount of work, but they hopefully demonstrate one possible method of capturing information for information retrieval. All of the searching forms use the "Next" button to move to the "next" step in a query. If a user specifies a boolean operator, the form is redrawn to add an additional input box for all the repeatable elements. So in the following screenshot, for example, the "AND" operator has been specified:
And the result is that an additional set of options is made available:
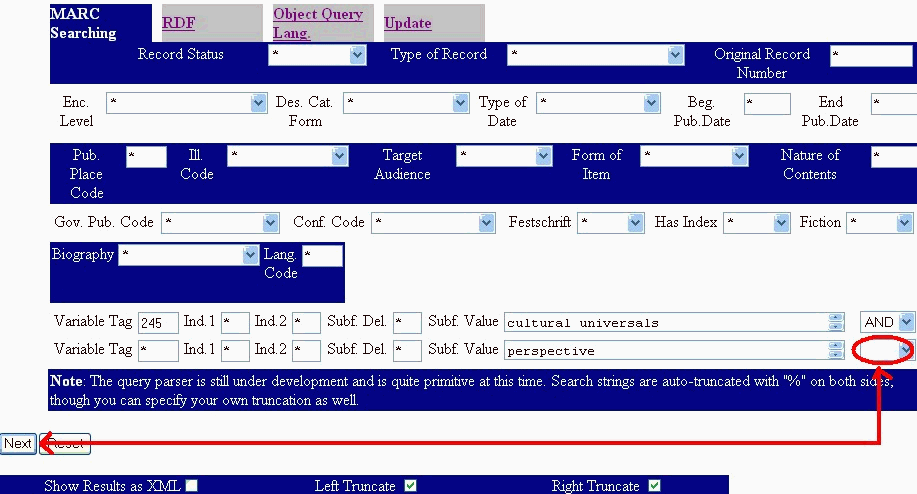
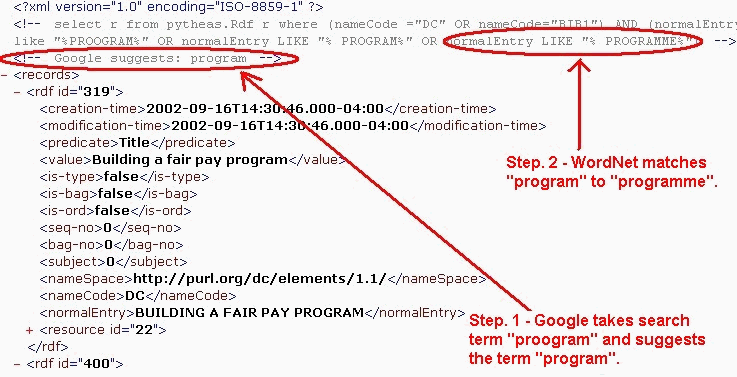
RDF searching shows how WordNet and the Google API are brought into the process. Using the RDF data model, search terms are matched against about 10,000 nouns from WordNet, and then additional terms are used for the query. Terms are also passed to Google's SOAP-based "suggest a term" service so that a search on "proogram" yields the following:
A Note on Recursive Data Models
One of the difficulties of mapping models like Topic Maps and RDF to a database is that they incredibly recursive. For example, in RDF, you make "assertions" about a resource, but you can qualify the "assertion" itself with an infinite amount of addition RDF statements. There are various ways of dealing with this but the approach in PYTHEAS has been to add an element that "points" to what the object is about and to supply a mechanism to support queries without requiring endless "drilling" down into multiple tables. To get a sense of this, consider our table view of Topic Maps:
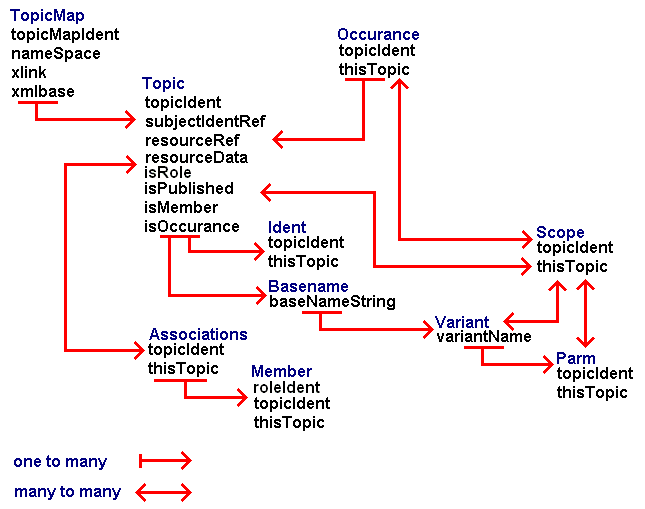
Almost everything in a Topic Map is a "topic" that is mixed and grouped together in numerous ways to express relationships. We define a boolean element for high level searching so that queries like "find me information where William Shakespeare is a member of an association" can be carried out without cyclical table lookups, e.g., where basename="William Shakespeare" and isMember=true. Some RDF databases take the approach of generating tables on the fly but the important aspect is to be able to pull out and query the relationships that have been added to the database.
Client Environments
PYTHEAS is exposed as an XML resource to any editing tool that can work with XML, from simple text editors to complex XML applications. However, there are advantages to constructing client applications that are fully "MARC aware. XML tools tend to be "document-centric, which is highly useful for presentation of content, but editing hundreds of MARC records as individual documents may be very inefficient in a large collection.
It is envisioned that staff client applications will be browser-based and utilize Mozillas XUL (XML-based User Interface) tools and LiveConnect. XUL maximizes the potential of the web browser as an application engine while LiveConnect can step outside of the stateless constraints of the web for staff applications. The standard stateless web model is viable for public side information retrieval and content presentation purposes. None of the client software is available at this time, though if you want to maximize your browser experience, XUL is definitely worth a look.
Object Query Language and Lazy Loading
Object Query
Language (OQL) is a mechanism supplied by Castor to use a high level query
language for retrieving information while generating SQL underneath to interact
with RDBMS Tables. For example, we can issue the query:
Lazy Loading is a
mechanism to minimize the amount of object loading required in the middleware
when pulling records from a database. It makes a tremendous difference in the
response time for queries and Castor can also use the LIMIT keyword to cut back
on the amount of work performed by the database itself. Next Steps The
distribution only includes one stylesheet, these are not hard to do and at least
several should be added to the mix. The basic framework is in place for handling
SOAP but the list of services that make sense for handling by SOAP needs to be
defined. The parsers need some attention and the web form processing logic
should really be revamped. It would make more sense to use the
DOM to set up a form object to process
repeatable fields than the current approach, and it would be worth investigating
Struts and the
Java
Form API to bring together a high level of web functionality at the
presentation level. Although this work is somewhat "java-centric", it would be
possible to use the same approach in other environments. The table mappings are
independent of the middleware, and the query tools can be used to see how the
SQL pulls the information together. The key to PYTHEAS is XML, not the
underlying programming, exposing library resources via XML opens the door to
plugging into many other environments.SELECT b from pytheas.Bib b where tags.subfs.subfValue LIKE "%unix%" and
langCode="eng"
and retrieve the XML representation of our record. You can
use the query tool with Castor to experiment with the database and also to view
the SQL that Castor generates for each OQL statement.
We welcome contributions, sage advice, and/or any kind of
feedback in all these areas.
1. Pytheas (b. 300 BC) was a seaman from the Greek colony of
Massalia who mapped a trade route to circumvent what was then a Phoenician
monopoly on the tin trade, much like Linux
and other open source initiatives are circumventing traditional software
vendors. For more information on this project, see the background
paper (in glorious RTF format!). Revision History
2.
I have sketched out some thoughts on LAFs in The End of the ILS,
InsideOLITA.
Fall/Winter 2001.
3. Of course, such restraint is completely abandoned in The Semantic Web & Libraries,
InsideOLITA.
Srping/Summer 2002.
23-March-1999:
Document first made available
31-March-1999: Extended
table layouts
04-April-1999: Added section on client
environments
12-April-1999: Expanded section on client
environments
17-May-1999: Added section on development
roadmap
25-June-1999: Link to PYSOCK added
09-July-1999: Client environment section modified
12-August-1999: Work on crosswalk
20-September-1999: Examine linkages with Mozilla
15-November-1999: Decision to split PYMAN into "standard" and
"MOO-enabled"
29-November-1999: Added link to MARC
Editor, more info on client environments
15-December-1999: Revamped LiveConnect to work with both Netscape and
Internet Explorer
05-January-2000: Decision to move
everything to java (sobbed a lot)
02-February-2000:
Existing code made available
05-April-2000: First
java-based version made available
01-July-2000: Work
started to utilize EJB and Castor.
11-November-2000:
First distribution to use Castor.
12-December-2001:
MARC Loader and demo files to be made available.
6-July-2002: Demo link added.
18-September-2002: Distribution released with SOAP & Topic Maps.
Last updated:
Date: 17-September-2002 by Art Rhyno <http://www.uwindsor.ca/library/leddy/people/art/>